
Building LingoShadow
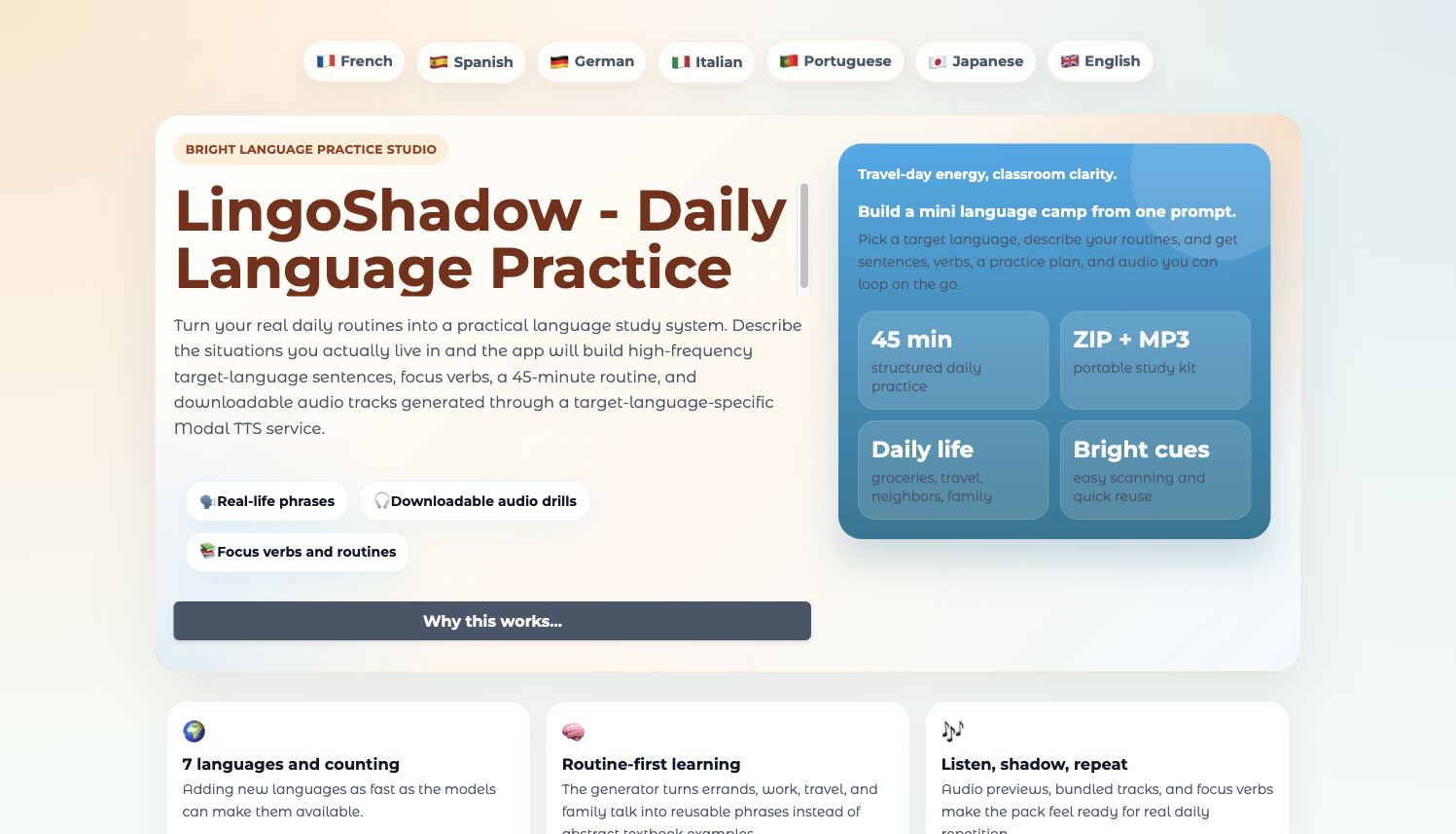
Building LingoShadow
I built version one of this app from the gym wiht my buddy, Codex. It’s really a different world for software development now. 😅
Anyway, I had been watching videos about language learning, shadowing, and the idea that you can get surprisingly far by practicing the sentences you are actually likely to say. Not random textbook sentences… that’s how we all learnt to speak as children, isn’t it? We repeated the phrases we heard in the contexts we were growing up in.
So the first prompt to Codex was basically: let’s make a Gradio app where I describe my normal life, choose a target language, and get useful sentences plus audio… and then I passed codex some of the links to the videos I had watched so it would figure out more context from the transcripts. With an agentic coding assistant, whenever possible, show, don’t just tell!
The default language would be French, of course, since that’s the only international language apart from English for which I can hope to catch a translation model in a lie. 😅
And that’s how LingoShadow was born: a daily language practice app that turns your real routines into a small study pack.
The Core Idea Was Not The Model
The first version was already fairly clear:
- ask the learner to describe their daily use cases
- generate target-language sentences around those situations
- include useful verbs
- create a 45-minute practice routine
- generate downloadable audio
- package the output so it can be used away from the app
That last part was important. I did not want a toy that only works while the browser tab is open. If the app is for practice, the output has to travel with you.
This is one of the biggest lessons from the project: for learning tools, the artifact matters.
A nice response on screen is fine. A ZIP file with audio tracks, a sentence table, verbs to review, and a routine is better. It turns the model output into something you can actually use on a walk, in a trotro, at the gym, or while pretending you are about to become fluent this week. 😄
Lessons
Audio Gotchas
-
The first audio packaging idea was too granular: one sentence per audio file. That sounded organized, but it would have been annoying in real life. Nobody wants a folder full of 10-second clips? So switched to tracks of up to 20 sentences.
-
The second issue was the text-to-speech voices. An English TTS model reading French is the funniest thing you will ever hear. When I heard the model pronouce “je vais” as “je va-ees” I knew we had a problem 😂. Fortunately, with some Googling and after sending Codex off to do some research, we finally found a shortlist of good TTS models for a subset of the languages I was considering.
-
The third issue was the audio file formats. We started out with WAV audio files, and it ran fine until I tried to share my study pack with an aspiring polyglot like myself. I couldn’t send it, even though I could play it. It turns out phones like MP3. People share MP3. Audio players understand MP3. WAV, apparently, is very yesterday… and so we had to throw in MP3 to WAV conversion.
Text-to-Speech on Modal
The audio work led to a chain of practical questions of two kinds:
Sentence generation
- should there be a break between sentences?
- how slow should shadowing audio be?
- should we slow down speech itself or just add padding?
Platform & architecture considerations
- can the workload live on Hugging Face or is it time to bring in Modal? (Spoiler alert, it was)
- can cold start begin when the page opens?
- should audio generation be split across workers?
The app needed a TTS service, backend routing, warmup behavior, progress feedback, and failure handling. The final stack routes target languages to different TTS models: Kyutai for English/French, MMS for German, and Kokoro for Spanish, Italian, Portuguese, and Japanese. 😫
Behind the language selection dropdown buttons, many routing decisions were taking place with anticipation for what a user would do next, in order to minimize system latency.
Multilingual Is A Routing Problem
Early on, it would have been easy to pretend one model could do everything well enough. But language apps punish vague thinking.
Text generation, translation, and speech are different jobs. A model that is good at writing practice sentences is not automatically the best translation model. A TTS model that speaks French well may not be the right choice for Japanese. And if the user selects German, the app should not quietly fall back to a French voice and hope nobody notices.
So LingoShadow ended up with a small-model stack rather than a single magic model:
Qwen/Qwen3-8Bfor sentence generationCohereLabs/tiny-aya-globalfor translation- language-specific TTS backends for audio
Each individual model stays comfortably under the hackathon limit, and we disclose the stack in the app.
Progress Feedback
Nobody likes to click on a button and wonder whether something is happening or the page is hanging.
Since study-pack generation takes time, workign through multiple stages of calling a generation model, translating, building audio, zipping files, and waiting on a remote TTS service, if the UI just sits there, people assume it is broken.
So progress feedback became a real feature:
- show that the build has started
- show sentence generation progress
- show audio packaging status
- keep the success state obvious
- add timestamped download names
- make the maximum sentence count sane for mobile use
Boring wins a lot in software.
Mobile Responsiveness
In the good old days of writing code by hand, when you had a problem with mobile views, you sat down with CSS media queries and fought with different padding levels and margins until you wanted to cry. Oh, the joys of trying to center a button. 😄🥲
Today, you tell your agent “Look at the mobile view in chrome and work out all the kinks”. Actually, you should be able to write a better prompt than that to get it in one shot, but it’s the same idea: not your job.
That’s all I’m going to say here. God bless coding agents.
Conclusion
This app has been my favourite side project in a long while. I’m actually going to be using it.
Like, I built something that speaks Japanese in one weekend. I’ll call it… the future is here.
✌🏾😎
You can try LingoShadow out here: https://huggingface.co/spaces/build-small-hackathon/lingo-shadow-daily-language-practice